In modern times, the first individual to foresee how technology could help
people communicate on a global scale was Samuel Butler. A contemporary of
Darwin, he wrote in 1863;[1]
"I venture to suggest that ... the general development of the human race to be
well and effectually completed when all men, in all places, without any loss of
time, at a low rate of charge, are cognizant through their senses, of all that
they desire to be cognizant of in all other places. ... This is the grand
annihilation of time and place which we are all striving for, and which in one
small part we have been permitted to see actually realised"
He was actually thinking of how the electronic telegraph might be used, then a new invention, but arguably in talking about the senses, he was also the first define a need for what is now called "multi-media" comunication. Furthermore, his phrase "desire to be cognizant of" expresses succinctly the need to be able to index and search for information, and to avoid being overloaded with useless information! Butler was followed by other prophetic scientists, such as H. G. Wells in 1937 imagining a world brain based on a permanent world encyclopaedia, or Vannevar Bush in 1945 proposing a technological solution to the problem in the growth of knowledge in the form of MEMEX, a multimedia personal computer.
The first problem relates to the fact that e-mail is predominantly a "push" mechanism, in that only the sender has control of any message and its content, and the recipient plays an essentially passive role in the process unless they choose to actively respond and become a sender themselves. Typically, an scientist might expect to receive anywhere between 5-50 e-mail messages a day, and in reality will probably choose to carefully read only perhaps 10% of these, and to respond to even fewer. Much of the remainder is often discarded unread, particularly the "spam" or junk e-mails that have became a serious problem in the late 1990s. After a few months, in and out (received and sent) mailboxes more often resemble "information graveyards", and few people keep old messages more than a year or two. In reality, e-mail has (with one important exception) changed very little since its invention in the 1960s, and has become perceived as a very noisy communication medium, more akin to the informal telephone call, than a scholarly and permanent communication method.
The second problem is that most e-mail has traditionally been based on
free-form text, which has little pre-defined or standard internal structure and
hence where the semantic content of the message cannot be easily indexed and
hence searched for. To paraphrase Samuel Butler, much of it is what we do NOT
desire to be cognisant of. Perhaps a specific example can serve to illustrate
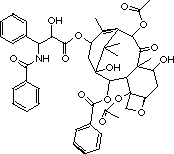
how difficult a communication medium it can be. If two chemists wish to
communicate to each other the detail of a molecular structure such as taxol
(Scheme 1), with as little risk of error as possible, they would probably NOT
try to achieve this using the telephone. They might succumb to exchanging fax
messages, but they would soon realise that to usefully apply the received
structures, they would have to redraw the diagrams using a suitable computer
program, with all the risk of error that does introduce.
Around 1992, the first enhancement to e-mail which has the potential to address some of these limitations was proposed by Borenstein and Freed [3] in an Internet standard known as MIME (Multipurpose Internet Mail Extensions), which allow a separate datafile to be enclosed (or attached) with an e-mail message. Interestingly, the first "M" of MIME is sometimes mistakenly intepreted as standing for "Multimedia", and here again we can see Butler's vision of the use of all our senses being implemented. This datafile could in turn be processed by an additional program presumed resident on the recipients computer known as a "helper". The first applications of MIME evolved during the late 1990s to exchange generic and standard attachments such as Microsoft Word documents, or individual graphical images such as the one above for taxol. This indeed was the mechanism by which this article was sent to the editor!
A very recent extension of the MIME method to a more focused scientific area such as chemistry3 (the so-called chemical MIME types) has now permitted, at least in priciple, an error-free exchange of a visually comprehensible and instantly usable expression of e.g. the taxol molecule. Because information received in this manner can have a precisely defined semantic content and a standard or documented structure, it can be in principle easily indexed and ultimately searched for by the recipient or sender. Use of the MIME mechanism as as carrier of high value scientific information has hitherto not received the uptake it deserves amongst the community, but as better e-mail software which supports such methods becomes more routinely used, this is expected to become a standard scientific tool of the future.
1. The first was the adoption of a so-called structured document language known as HTML (Hypertext-markup language), and this was possible because a set of guidelines on how to design such as language (known as SGML) were by 1989 reasonably mature and accepted as a de-facto global standard. The use of HTML in turn enabled documents to be easily indexed and retrieved. It is rarely realised that within a year or two of the widespread global deployment of the Web and HTML around 1994, the Internet had been almost comprehensively indexed, and a variety of so-called "search engines" such as Alta Vista were in use. HTML in turn is now evolving into XML (Extensible Markup Language),[5] which will allow scientists to express more richly than they could with HTML alone their own subjects, ultimately allow their subject to be indexed and searched for. Now at last, one can see how Samual Butler's vision of "finding all that we desire to be cognizant of" might be close to realisation for scientists.
2. Berners-Lee realised that if a document could be expressed in structured form, then finding individual components within any individual document was as important as finding the document itself. He went further, and defined the "resource" as the important principle of scientific communication. He therefore used two components of the Internet, the ability to define almost any device connected to it via an address known as the "IP" address, and the MIME extensions referred to earlier to create something called a "URL" (Uniform resource locator). This locator could be inserted into a document, or indeed into programs or into databases in the form of a hyperlink, and this could serve to establish a network of links, or context, between diverse multi-media resources. Created by say a chemist, such a rich construct of links can serve to define knowledge within a subject, rather than just simply a collection of information.
3. The final design feature is a little more arcane, but no less important. The Web was designed as a "stateless" mechanism for "pulling" resources from a server. Up to 1989, use of the Internet was predominantly as a point-to-point communication channel between two devices. The channel whilst it was open reserved vital bandwidth by preserving the state of the link (essentially a history of the entire session) , and it could often remain open for hours. Forseeing that his creation of the hyperlink meant opening one-to-many channels, Berners-Lee stipulated that each URL when invoked should close each channel after data transmission was complete, a design that has indeed allowed the 100+ fold increase in traffic that has resulted.
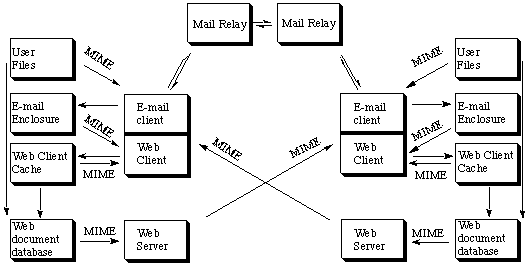
We have described how both e-mail and then the World-Wide Web have introduced
global mechanisms which can act as links between information resources to
establish the connections between different scientific disciplines, and which
now form the backbone of much modern scientific communication. An overview of
this modern infra-structure is shown in the scheme below, which charts the
relationship between e-mail and the Web, and how the MIME standards can be used
to link the two technologies. The original article describing this should be
consulted for further detail.[3]
The case study starts at the normal point of an author preparing a conventional
manuscript for publication, in this case for the Royal Society of Chemistry journal ChemComm. The article
describes how several new molecules have been prepared, how their structures
have been determined, and how information obtained from instruments which
measure their spectral properties relates to their structures.
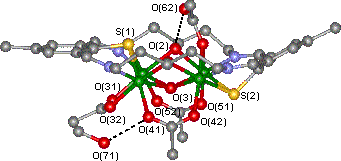
 for 3D view"
for 3D view"
You can see for yourself that expressed on paper as in Figure 1, it can be
difficult for the reader to see the three dimensional perspective of the
molecule, or to identify individual regions or atoms which might be obscured by
other atoms. Using a chemical version of the MIME mechanism,3 the
reader of the electronic form of this journal article can produce a rotatable
3D model of the molecule on their computer screen, which can be viewed by them
from whatever angle and magnification they wish.
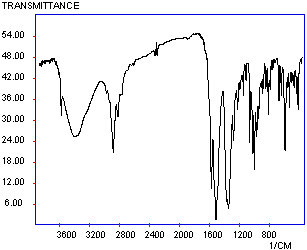
 to acquire the JCAMP Digital Spectrum"
to acquire the JCAMP Digital Spectrum"Associated with this molecule is an infrared spectrum (Figure 2), which for the reader of the printed page is "what-they-see-is-all-they-get". Using a slightly different Internet tool known as the Java applet, the e-reader can acquire the original data as recorded from the instrument, and again expand regions of the data, measure distance between peaks, or integrate the area under the peaks. The two sets of data can also be inter-linked. For example, if the reader selects a peak in the infrared spectrum, the atoms associated with the molecular vibration assigned to that peak can be highlighted in the 3D molecule display. Because the data is available in digital form to the user, it can be transferred to other programs and tools. For example,[7] the 3D coordinates of the molecule could be acquired and transferred to a spectral simulation module, where the vibrations can be modelled theoretically. The theoretically derived infrared spectrum could then be overlayed with the experimental version to see how well they compare. In effect, what has happened is that the reader of such an e-journal article can have almost immediate access to the authors' original data, and can apply that data to their own purposes and scientific needs.
Even in 1998, the abandoning of much of the electronic enhancements illustrated above (Figures 2, 3) in order to achieve such printability was still the norm. The advent of electronic-only journals such as the Internet Journal of Chemistry[10] suggests that this situation may change, although no-one expects the process to occur rapidly. In part, this is because the problems of long term (ie > 10 years) archival have not really yet been addressed. Some of the electronic conferences noted above have been archived on CD-ROM, preserving all the active chemical functionality, but often being tied to specific features of the Word-Wide Web (such as the browser version) which may make it difficult to avoid longer term obsolescence. Other electronic journals adopt archival on CD-ROM of generic page description formats such as Adobe Acrobat which in effect emulate paper, but which are less amenable to chemical "enhancements". One discrete trend that the Internet and electronic dissemination will undoubtably bring about is the so-called "aggregation" of individual journals into large databases of scholarly and searchable content. Commercial pressures seem more likely in the short term to threaten the existence of individual journals than to result in their scientific enhancement.
The focus of this of necessity short article has been on e-mail and the Web. There is however something of a continuum of collaborative methods available between these two extremes. Mention should perhaps be made of an interesting experiment that started in late 1997, that of the "virtual chemistry lecture", which made use of Web technologies to deliver a keynote lecture, followed by panel discussions and eventually moderated comments from a virtual audience of some 350 registrants to the event.[11] The lecture slides were themselves hyperlinked to other on-line materials, and were chemically enhanced in a manner similar to that shown in Figures 2 and 3. It seems unlikely that such events will in the near future supercede the more conventional delivered talk to a real audience. Indeed, as the author of original lecture, I followed this up by giving the same lecture to a live audience a few weeks later. Whilst the latter allows more ephemeral devices such as humour to be employed, only time will tell which of the delivery methods has the longer term impact on scientific communication.
This very brief overview of Internet-enabled scientific communication merely scratches at the surface of what is possible. Of course, communication is more than just about the technology, it is about finding methods that the scientists find helpful, and where the technology does not distract from the science. The must be the challenge we face over the next decade, in reconciling technical wizardy with genuinely enhanced scientific perceptions. We must not also forget the legacy we must bequeath future generations, for whom the current technology will seem quaint indeed, and who must not not lose access to the knowledge because of this. Other brain teasers include how to handle to issues of copyright resulting from such "active" content. There remains much to be done, but it would be fair to say that the potential for changing the some of the ways that scientists can communicate with each other is substantial.