HTML is an open human-readable format based on 7-bit ASCII text, unlike 8-bit closed binary mode document formats readable only by using proprietary programs. Because the internal structure of a document written in HTML is defined using well-formed markup instructions, building an index from a diverse collection of such documents, which might have been created by many different authors using a variety of styles, remains a relatively simple technical operation. The first such index known as Lycos was created in 1994 and used as its source around 30 million HTML-based documents, retriving these documents from the Internet using a so-called "spider" or "robot". Much imitated subsequently, such global indices now form perhaps the most important mechanism for classifying, ordering and retrieving information from Internet-based document and data collections.
By design a very simple and specifically a general markup language, HTML allows for only very basic internal document structures to be defined. It has little syntax for defining subject specific "information components" and serves specific subject areas such as chemistry particularly poorly. The limitations of HTML were recognised early on, and a number of initiatives to increase the quality of text-based indexing of such documents were started. One of these, known as the Dublin Core (DC) project, attempted to define a small and limited set of so-called metadata elements to be defined with a document, and which an index engine could use to achieve a more valuable ranking of information and identification of data present within the document.1
The term metadata can be a somewhat elusive concept to fully grasp; at its simplest it is often described as "data about data". An analogy serves to illustrate better its meaning. A restaurant exists to serve food to its customers, but it first has to entice these customers into the restaurant. Most restaurants do so by creating a menu of dishes available to potential diners, and placing this in a prominent position outside the restaurant. The menu serves as metadata describing the food, indicating the price of the meal, and perhaps including some information about the origins of the dish, the chef that might cook it, the "hotness" of oriental dishes, and so forth. Such information is normally sufficient to allow prospective diners to decide whether to enter the restaurant, but of course in no way can it be described as a replacement for the full gastronomic experience. DC is an attempt to create the equivalent of a restaurant menu for HTML document collections. We emphasize that a schema such as the Dublin Core should NOT be considered as a complete solution for compensating for the limitations of HTML itself, but rather a mechanism for enhancing the usefulness of such documents. DC is of course not limited just to HTML collections, but can be expressed in many other types of data and document types.
In this short note, we will describe the more useful DC metadata elements, and how they can be used to create an enhanced-value index for the ECSOC-1 and ECSOC-2 HTML document collections. The origins of DC as a bibilographic descriptor devised primarily by librarians for their own use also means that its direct usefulness for enhancing the "chemical" menu of a HTML document are quite limited. We address this by introducing a further proposed schema based on what we term chemical meta-elements, and show how on the basis of two articles published in Molecules a more accessible chemical index could be constructed. Finally, we note that to achieve a more finely grained chemical resource, the answer lies not in devising more complex metadata schemes but in employing a more finely grained and specific markup based on the new XML, or eXtensible markup language. One chemical implementation of XML known as CML (Chemical Markup language) has recently been described.2
http://www.ukoln.ac.uk/dcdot/, and then entering into the form presented the URL of the document being edited. Most of the values for the fields were already present in the majority of articles presented at the ECSOC conferences, although clearly some decisions on behalf of authors did have to be made. It would be much better of course if these values were routinely supplied by authors themselves when preparing the articles. Such procedures were in fact followed in the submission procedures for the ECHET98 electronic conference held in 1998.3
| Table 1. Selected Elements of the Dublin Core Schema | ||
|---|---|---|
| Element Name | Description of the element | Deployment in HTML 4.0 |
| HEAD | Specifies the location of a meta data profile. | <HEAD profile="http://purl.org/metadata/dublin_core"> |
| DC.title | Title of Document | <META NAME="DC.title" CONTENT=""> |
| DC.creator | Author(s) of article | <META NAME="DC.creator" CONTENT=""> |
| DC.subject | Keywords describing article | <META NAME="DC.subject" CONTENT=""> |
| DC.description | Abstract of article | <META NAME="DC.description" CONTENT=""> |
| DC.date | Date of article (submisson date) | <META NAME="DC.date" CONTENT="1999-03-25"> |
| DC.publisher | Address of authors | <META NAME="DC.publisher" CONTENT=""> |
| DC.type | Type of Document. | <META NAME="DC.type" CONTENT="chemical"> |
| DC.coverage | Field of coverage | <META NAME="DC.coverage" CONTENT="organic synthesis"> |
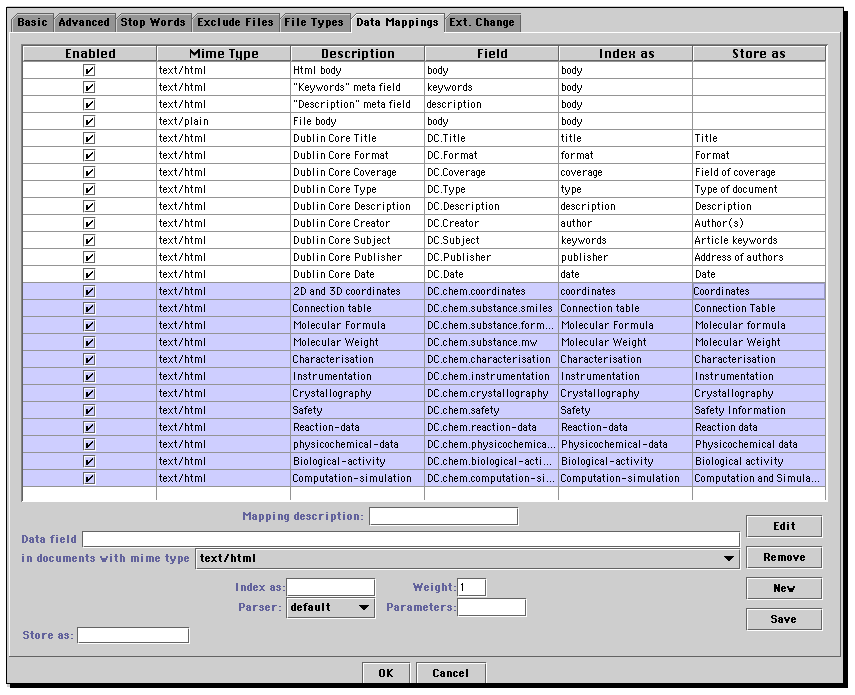
By including elements of this type, in effect the author of the document is declaring that (a) some form of chemical data will be associated with the document, or its children and (b) identifies the nature of that content to allow subsequent specific parsing of the data by additional software agents if desired. It is not in general intended that finely-grained chemical data be included within the content of the DC.chem declarations, although some types of chemical metadata such as the molecular formula, the molecular weight or a simple atom connection table such as the SMILES string may be valuable. The purpose of such entries is to assist in more extensive analysis of the document should this be desired, and to help in identifying the resources that will be needed to perform this analysis. This specific task can be implemented via the declaration of a SCHEME attribute. For example, the metaelement
<META NAME="DC.chem.coordinates" SCHEME="PDB" CONTENT="chemical/x-pdb">
could be used to automatically invoke an external parser from the search engine capable of analysing the meta-content content of the particular file the content of which is specified by the scheme "PDB" and the type by the MIME identifier chemical/x-pdb. The PDB format for example has meta identifiers such as TITLE, AUTHOR, KEYWORDS etc which can be usefully indexed. A full parsing of the complete content is left to specialised chemical search engines. Such an external parser has in fact been used (albeit by manual and not automatic configuration) for the document collection indexed in this example.4 If necessary, an associated LINK element can be included in the metadata to enable any agent, automatic or otherwise, to acquire a formal definition of the metadata type, and if necessary the appropriate software resources to analyse the content of the document (for example a remote applet to be used as an external parser).
We also note that whilst the declaration is preferable to the alternative , the latter is far more likely to be compatible with any existing "structured field" index engine (such as htdig or JObjects used in these examples. The former would require specific modifications to these tools to recognise the scheme attribute. For this reason, we have used the latter format, whilst recognising that should suitable support for scheme declarations become available, the latter can be easily superceded.
| Table 2. A Chemical Metadata Schema | ||
|---|---|---|
| Element Name | Description of the element | Deployment in HTML 4.0 |
| HEAD | Specifies the location of a meta data profile. | <HEAD profile="http://www.ch.ic.ac.uk/profiles/chemical/"> |
| DC.chem.coordinates | Molecular coordinates | <META NAME="DC.chem.coordinates" SCHEME="pdb" CONTENT="chemical/x-pdb"> |
| DC.chem.substance.formula | Formula constitution | <META NAME="DC.chem.substance.formula" SCHEME="formula" CONTENT="C22H30N6O4S"> |
| DC.chem.substance.smiles | Connection table for molecule | <META NAME="DC.chem.substance.smiles" SCHEME="smiles" CONTENT=""> <link rel="DC.chem.substance" type="text/html" HREF="http://www.daylight.com/dayhtml/doc/theory/theory.smiles.html"> |
| DC.chem.computation-simulation | Presence of computed or simulated property | <META NAME="DC.chem.computation-simulation" SCHEME="MOPAC" CONTENT="PM3"> |
| DC.chem.biological-activity | Biological activity | <META NAME="DC.chem.biological-activity" SCHEME="..." CONTENT="1-"> |
| DC.chem.safety | Type of chemical safety information | <META NAME="DC.chem.safety" SCHEME="..." CONTENT=""> |
| DC.chem.characterisation | Characterisation mode of molecule | <META NAME="DC.chem.characterisation" CONTENT="MP, HPLC, IR, 1H NMR"> |
| DC.chem.instrumentation | Associated instrumentation | <META NAME="DC.chem.instrumentation" CONTENT=""> |
| DC.chem.physicochemical-data | Molecular properties | <META NAME="DC.chem.physicochemical-data" CONTENT=""> |
| DC.chem.reaction-data | Reaction classification | <META NAME="DC.chem.reaction-data" SCHEME="GRINS" CONTENT=""> <link rel="DC.chem.reaction-data" type="text/html" HREF="http://www.daylight.com/dayhtml/doc/theory/theory.grins.html"> |
| DC.chem.crystallography | Crystallographic information | <META NAME="DC.chem.crystallography" "SCHEME=BCA" CONTENT=""> |
Figure 1. Chemical Extensions and the Dublin Core Configuration Settings
Figure 2. Deploy a Field Search Applet for Dublin Core fields.
For chemical metadata declarations, this format allows searches of specific areas of chemistry such as molecular coordinates, reaction-data etc. etc.
Figure 3. Deploy a Field Search Applet for Chemical fields.
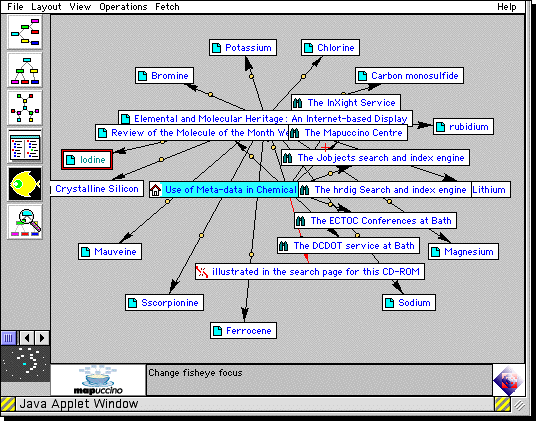
Figure 4. A Concept Map generated using the Mapucinno System6