The phenomenon which is now called the Internet is scarcely a quarter of a century old, and yet is now a major enabling tool for scientists. This review will focus on the historical aspects of how this tool came into being, from the particular perspective of the author's own experience with it. An introduction to the latest manifestation, known as the World-Wide Web, is followed by examples in two areas of scientific communication which have been affected, electronic conferences and distributed teaching materials, with special reference to chemistry as a topic. Many of these examples are illustrated with citations to Internet addresses which will enable the interested reader to explore the real thing.
The "Internet" is a phenomenon of the late twentieth century, in the way that television was of the middle of the century and the telephone of the early part. Unlike these last two seminal developments in communication, the Internet is still growing up. The latest addition to the family, the World-Wide Web, was brought into being by physical scientists who wanted a global mechanism to communicate with each other efficiently, simply and most importantly accurately. Invariably perhaps, as the parents watch their offspring approach adolescence, they feel the teenager spends too much time with popular music and other recreational activities, at the expense of serious studies. I argue in this article that in fact an innovative scientific tool is indeed growing up, and that many aspects of scholarly communication may be permanently changed as a result.
The Internet is a matrix of networks and computer systems linked together around the world. How it came into being and its subsequent evolution is described from my personal perspective. This is followed by some specific examples of the effect the Internet has had on everyday scientific work patterns and modes of communication, and some of the sociological issues that result. This article is however not intended as a handbook in the use of the Internet, since this is well documented elsewhere.[1]
History of the Scientific Internet
Two unique aspects of the Internet differentiate it from most other forms of communication. It originated in the early 1970s as a defence sponsored university experiment in how a global communications infra-structure could be designed to survive the widespread destruction of war and other disasters. Secondly, because of its academic origins, it was not driven exclusively during its formative years by commercial requirements and pressures, or by the needs of the conventional publishing industry. As a result, the basic infra-structure for the Internet has until recently been funded largely via University funding bodies or via sponsorship of university research projects. These origins in academic freedom encouraged an ethos of making much material and information freely available to all users, although with the penalty that the quality could be highly variable. There is an analogy here with the history of television: the early receivers were very expensive and the transmitted programs were rarely memorable.
Until about 1994, the Internet was relatively unknown outside the small circle of university researchers, and in many specific subject areas such as the molecular sciences it remained an esoteric mechanism, with a reputation for being less than easy to use. Change then came very rapidly. The reasons for this are best illustrated by describing my own experiences in applying the Internet to scientific activities.
In the early 1970s, I was working at the University of Texas at Austin in the development and application of a relatively new area of chemistry called "molecular modelling". This involved applying mathematical models to trying to understand the reactions and behaviour of molecules. This required access to powerful mainframe computers, then a very expensive resource that could only be justified by sharing it between many researchers at the university when it was located. Such mainframes required elaborate maintenance procedures and tended to be located in high security such as computer centres. Access to this resource from individual research offices was achieved using a campus telephone, via a device known as a modem and a data entry system known as a "teletypewriter". Using this, one could type corrections to program code stored on the central computer, issue arcane instructions to compile or to execute these programs, and receive a limited amount of data back from the program in the form of lines of text 80 characters wide printed on a local paper spool. Molecules were represented by lists of atomic numbers, bond lengths and angles, and connectivity information; hardly the most intuitive way of showing their shapes and properties!
Matters had improved by 1977, when the teletypewriter was replaced by a device known as a Tektronix graphics terminal. Both text and images were created on the screen from vectors, the defining X and Y coordinates being transmitted from the remote computer using a cable directly connecting the two devices. A small molecule could be represented with a thousand or so such vectors, although only in monochrome and it could not be rotated in real time. No one off-campus could participate because the cable length was limited to a few hundred metres. At Imperial College, where I was now based, the computer graphics room was really only used by myself and the departmental crystallographer!
Around 1981, these direct wired connections began to be replaced by "switched" network connections, very much like digital telephone exchanges, and the rate at which information could be exchanged started its climb from the 15 characters per second (cps) associated with the original teletypewriter and the 1000 cps associated with the Tektronix terminal. Nowadays, a modern modem can send around 4000 cps and some people are beginning to use circuits a million times faster than the original teletypewriter. In the chemistry department at Imperial College in 1983, we started the task of wiring the department, and within two years had about 50 network connections installed. The era of a network connection available directly on a user's desktop had arrived, although the device resident there tended to be what is now called a "dumb" terminal. Curiously enough, when the first personal computers were installed in the department in 1983, the very first program installed was a Tektronix terminal "emulator" which made use of these switched network connections. Word processing on personal computers only came a little later!
By about 1982, the computer networks were beginning to operate on a national scale, but were not yet thought of as the "Internet". In the UK for example a set of network protocols (the "coloured books") had emerged to control the way data was transferred between computers on a national network called JANET (Joint Academic Network), and in the USA in the same year a different protocol known as TCP/IP had been introduced. Slowly, value-added information became available on these national networks in the form of on-line repositories of scientific information. The UK for example launched the Chemical Databank System at its Daresbury Laboratory and a few adventurous scientists began to learn the often obscure commands associated with custom programs that were necessary to retrieve such database information. The "graphical user interface" was still unknown, and information was exchanged in the form of text and Tektronix vector graphics. In 1984, a consortium of commercial information providers known as STN (Scientific and Technical Networks) began offering on-line access to Chemical Abstracts, the most complete source of indexed information for chemists. In the UK, this was available by using a leased circuit connection to Germany, where the database computer was located, but such specific connections were not yet regarded as the true Internet. Most chemists at this time were content at this time to leave the task of searching these databases to a librarian or an Information Scientist, and an individual rarely "browsed" the Internet.
By the late 1980s it had become apparent that the UK coloured book system was not being adopted globally, and that the clear "winner" was the TCP/IP system originating in the USA. Originally this protocol was only used within Unix workstations, which few scientists had in their offices because of the expense and their "user unfriendly" reputation. The real breakthrough for us came when TCP/IP software became available for personal computers, and in particular for the Apple Macintosh system. At Imperial College around 1987, we initiated a policy of connecting most of our growing Macintosh computer population to the network, ostensibly to promote the use of high quality remote printing, but also to raise awareness of what network resources in general could offer the user.
An increasing number of brave souls began using electronic mail (e-mail), as well as performing some on-line database searches for themselves. I still remember the surprise caused by my inclusion of an e-mail address in the header of a scientific paper I published in 1987; both at the editorial office of the publisher, who had no precedent for doing this, and amongst my colleagues who felt I would be immediately inundated by "junk messages" (one message a day was then considered excessive, nowadays I sometimes get 100). Adoption of the TCP/IP protocol on IBM style personal computers became more common with the introduction of the Microsoft Windows operating system, and by 1995 it had become normal to exchange routine memoranda by e-mail rather than by paper. So much so that historians and archivists now face genuine problems in preserving for posterity those routine exchanges from which history is reconstructed, but which are rarely saved in any permanent form by the users.
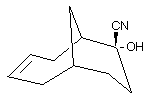
E-mail in the early days was restricted to text only. Chemists in particular felt highly frustrated that they could only express themselves in words, and not in the hieroglyphic diagrams we call chemical structures. How for example could a chemist clearly and simply describe the following structure using only text?
The need to send information for presentation to the user in forms other than text was only solved in 1993 via the introduction of another globally accepted protocol called MIME (Multipurpose Internet Mail Extensions). Using a chemical extension of this which we developed,[2] it is now indeed trivial for chemists to exchange structures such as the one shown above with their e-mail messages. Electronic mail is now widely considered as the first mature Internet mechanism to have a distinctive impact on the way scientists communicate with each other. For example, the scholarly peer review mechanism which most journals adopt for vetting submitted articles is nowadays conducted predominantly using e-mail.
Electronic mail was and still is regarded as being closer to conversation than to publishing, and in the late 1980s, the Internet had not had any significant impact on more permanent forms of scholarly communication. In 1988 I was invited to join the editorial board of the Royal Society of Chemistry, with a brief to advise on guidelines for theoretical and molecular modelling papers submitted to the society. Here the concern was that it could often be very difficult for a referee or a reader of a computationally based paper to try to independently reproduce the reported computed results. Supporting numerical and other information that could help do so was rarely submitted to the journal, and even then only in printed form. The subsequent transfer of such data to a computer was a manual and a very error prone process. I was convinced at that stage that we needed to have a global system within which the digital transfer of numerical data and diagrams such as the one above would be entirely trivial to accomplish. The sticking point was cost; it was difficult to imagine a publisher bearing this exclusively, particularly since this was not perceived as being a revenue generator. At this stage of course, scientific publishing was still regarded as an expensive activity in which cost recovery was largely borne by the centralised library model that had evolved in most universities in the early part of the century, a model which even then was falling apart as the costs spiralled upwards. The search was on for a suitable technical infrastructure that could achieve the objectives of increasing availability and reducing costs.
The World-Wide Web.
Also perhaps driven by costs, a scientist at the European laboratory for particle physics (CERN) started addressing this problem around 1989. Tim Berners-Lee, working with Robert Caillau, recognised that experiments in nuclear physics often involve tens, perhaps hundreds of scientists from all over the world who need to communicate efficiently, and most importantly, in a structured and error free form.[3] A single numerical error could easily ruin a vastly expensive experiment. Nuclear physics was also perceived by politicians of the time as hugely expensive, part of which was due to the large travel costs associated with bringing all these physicists together to conduct and discuss their experiments. If CERN was to sustain its funding from politicians, it no doubt seemed politic to develop a cheap and simple global mechanism that could form the basis for a structured and distributed collection of information. All the scientists should have easy access to this collection, but without the need to distribute an array of unmanageable user accounts and passwords for access to each computer where information was distributed.
Starting as an in-house system at the CERN laboratory, this mechanism gradually spread into the world's scientific laboratories, as university research laboratories began to install and mount their own document servers. The World-Wide Web as it became known (often called just the "Web") began in response to a scientific need, something often forgotten nowadays. It also was first seeded amongst small research groups who needed to communicate with like minded colleagues around the world. It was rarely started by existing organisations in charge of institutional computing infra-structure such as computer centres or libraries, nor were publishers and commercial software developers involved at the start. It was thus a phenomenon associated with key individuals, who often had a vision of what could be accomplished, and who did this with much enthusiasm but with little funding or local support. After just half a decade of progress, this is changing rapidly of course. One major company whose only products relate to the World-Wide Web now employs around 5000 people, and the role of the key individual now often seems submerged by the need for business acumen and marketing expertise. Interestingly, the early generation of "Webmasters", i.e. someone who develops and administers a local site, were almost invariably self taught and unpaid. Now a competent webmaster can command daily commercial rates of up to $1500!
The first key design feature of the system implemented by Berners-Lee and other colleagues at CERN involved an addressing scheme known at the URL (or uniform resource locator; a wonderfully cryptic description which nevertheless did not seem to dent its acceptance).The use of the word resource is seminal to understanding why this system has had such an impact. Originally in 1989, the resources referred largely to text based documents written in a new language devised for the purpose called HTML ((hypertext-markup language) and held on a specified computer system, a concept of course that some of us had been familiar with for 15 years or longer. What was new was that in combination with the now mature TCP/IP global infra-structure, the URL provided a simple way of uniquely identifying the location of this document, and most importantly, allowed the document to be referenced from within another document using a mechanism known as a hyperlink. The hyperlink concept itself was hardly new, having been around for perhaps twenty years from early musings by Ted Nelson, Alan Kay and other computer pioneers. The key was the association between the hyperlink concept and the global TCP/IP protocol. Because each document was in effect publicly accessible for reading (but not for writing), one could construct quite an elaborate collection of documents, held on many different computers all over the world, and the reader could access this collection as if it were a single coherent article on a particular theme.
The second far sighted decision was to create a new, and originally at least a simple, language to write the documents in. Unlike previous generations of portable document languages (Postscript, Rich Text Format, and other proprietary formats), HTML from the outset was meant to be non-proprietary, easily written and understood even without elaborate tools. It was also based on a set of guidelines known as SGML (standard generalised markup language) in which a clear distinction is made between the content of the document and its form (i.e. the manner of presentation of the document). The profound significance of this only became apparent a little later, when people starting developing methods of indexing and searching the Internet. Because the content of documents written in HTML is in principal at least strongly identified, indexing such a collection becomes much easier. Internet search engines are now big business, with some 50 million documents having been identified and indexed up to mid 1996. Unfortunately, the original elegance of the HTML language and its derivation using SGML guidelines has become significantly diluted by the recent pressures to create attractive looking commercial sites in which the "form" or appearance of the document begins to dominate over its content. The situation appears retrievable with the latest version of the language (HTML 3.2)science[4] in which some attempt is made to separate the form into what is called a style sheet, leaving the content to be handled purely by the HTML. Whether the community will adopt this solution and how it will be useful to science remains to be established.
Network resources other than simple text based documents were soon added. The "telnet" resource was introduced to allow a direct link between a document and a teletypewriter terminal style network access to a remote computer. Thus a document could serve as the starting point for say a database search, or any other terminal based traditional computing task. A "ftp" resource allowed the user to acquire intact onto their local hard disk complete files of information or entire working computer programs. Somewhat later, a "mailto" resource became supported which provided a link to the electronic mail that many people were already using. Such backward compatibility with earlier Internet mechanisms, together with the introduction an entirely new method of presenting information is probably the reason for the instant success of the Web. The development of MIME standards for including rich content in electronic mail came at just the right moment for the Web. MIME provided a mechanism for graphical images in the form of GIF (Compuserve Graphical Interchange Format) files to be added as resources. MIME also enable other departures from conventional printed materials to be introduced such as video animations, audio (and from our own work, chemical content). The latest resource to be added is the Java "applet", a self-contained program (computer scientists call it an object) together with data, which executes within the screen document, and with which the user can interact. Some specific examples of Web resources are shown in Table 1.
| http://www.lycos.com/ | A URL for a keyword search of the Internet |
| http://www.ch.ic.ac.uk/rzepa/science/ | A URL pointing to an electronic version of this article. |
| http://www.ch.ic.ac.uk/rzepa/ | A URL pointing to a GIF format image of the author |
| mailto:rzepa@ic.ac.uk | A URL to send an electronic mail to the author |
The breakthrough for the Web came around the end of 1992, and may also have been driven by politics. The USA government was becoming concerned at the cost of large university supercomputer centres. One such organisation, the National Centre for Supercomputing Applications (NCSA) had started to diversify its software development program to enable the more efficient use of supercomputers. They had been working on a collaborative scientific tool known as Collage, essentially a shared whiteboard area where two or more people could exchange ideas using the Internet. This evolved into a project to write a World-Wide Web browser called Mosaic, originally envisaged simply as a student project. Two of these students, Mark Andreeson and Eric Bina, subsequently became founders of Netscape Communications Corporation in 1994, famous for its overnight valuation when floated on the stock market. Mosaic was to be targeted directly at users of personal computers rather than just Unix workstations and it became widely available in this form in the autumn of 1993.
Mosaic innovated in three ways. Firstly, it functioned almost identically on all the major types of computer, including Unix workstations, Macintosh systems and PCs running Windows software. It was thus probably the first widely distributed program in the history of computing that actually achieved this feat. Secondly, Mosaic allowed images to be displayed as part of the document window (unlike the original Berners-Lee browser). When I saw Mosaic in action for the first time in May 1993, I remember being impressed at how very easy it was to use in comparison to all previous programs that made use of the Internet. It seemed a distinct improvement on another experiment in distributed documents known as "Gopher", which had been introduced around 1992 and which we had started using for our own experiments in scientific publication. Finally, Mosaic was distributed at no cost to the individual end user, then considered a most unusual business model!
My initial reaction in May 1993 however was to dismiss the World-Wide Web as irrelevant to my needs as a scientist. Why? Because there was absolutely nothing in my own subject area available for me to browse using this mechanism! I was still indoctrinated with a residual belief that the provision of information was exclusively the responsibility of publishers, whether commercial or learned, organisations providing database access, librarians and other information professionals. The realisation that working scientists could actually make use of mechanisms such as this to directly provide information was put into focus in September 1993 as a result of attending a conference in Japan of computational chemists (WATOC-93). The official conference photographer had been circulating widely, and we were invited to indicate which photographs of the meeting we would like to receive in due course by regular post. My suggestion to the president of WATOC Paul Schleyer, that we should use the Internet to disseminate these photographs more widely, resulted in my immediate appointment as the WATOC information officer! When our Web server at Imperial College started informal operation in October 1993, it was possibly only the 3rd or 4th such chemically oriented server in the world (the first, as a matter of interest, appears to have been started by Benjamin Whitaker at Leeds University, England, in November 1992).[6]
By December 1993, not only were the WATOC photographs available by this mechanism,[7] but I had mounted two complete lecture courses that I taught at Imperial College, and several research papers that we had recently published in conventional learned journals (following I might add a request from the publisher to be allowed to do so). Thus begun a project that has thus far lasted almost three years into how both teaching and research information in my own area of chemistry could be served by the new global Web. Before going on to illustrate some of the ways in which a science such as chemistry can now be presented, some discussion on how the adoption of this medium has proceeded in my own discipline of chemistry might be instructive.
By January 1994, I had become aware that along with generic standards such as the HTML definition for how to "mark-up" a document for presentation on the Web, molecular scientists would need their own standards for how to exchange what was dear to their own hearts, namely chemical information. Although as I note above, a small band of molecular scientists had been using the Internet and its predecessors for perhaps 15 years, no-one had actually proposed or developed any standards which made specific use of the special features of the Internet. Along with Peter Murray-Rust working at the pharmaceutical company Glaxo, and Benjamin Whitaker at the University of Leeds, we proposed a standard called chemical MIME, an extension of the MIME e-mail standard noted above. This was first discussed on a wider global stage at the first World-Wide Web conference held at its birthplace CERN in May 1994, as part of a chemistry workshop.[8] Unlike subsequent conferences, this one had a fair sprinkling of scientists in attendance, and there was ample opportunity to meet many of the key players in person and spend time talking to them. During this seminal event, other key aspects of the Web such as Virtual Reality Modelling Language (VRML), the development of electronic conferences, journals and "virtual" schools had their genesis here.
Current Science on the Internet: Two Examples.
So how do concepts such as a MIME standard help to present a scientific subject such as chemistry? It is not my intention here to delve into the technical details. Suffice it to say that MIME offers a way of clearly and unambiguously identifying the content of a document referred to by a URL pointer as having structured chemical information. This then allows the user to act upon this information when it is received by the World-Wide Web browser. Because this is so important to chemists, I will try to illustrate below how a document can be chemically enriched. Of course, other scientific disciplines can also benefit in their own areas. As noted above, a document can be made to reference an Internet resource by including a hyperlink to this resource. A text based document would look something like this;
<A HREF="http://www.ch.ic.ac.uk/atp.pdb">Click here to view molecule</A>
Only the "Click here to view molecule" component of this line is actually displayed on the screen by the browser. Of the rest, the <A...> and </> portions define the start and end of a so called anchor, which is how the hyperlink is actually defined. HREF of course stands for hyperlink reference, whilst the URL is enclosed between double quotes. In this example, the URL points to a computer file in what is known as Brookhaven Database format. This is one of the (relatively) standard ways of expressing a molecule as a collection of atoms and groups, along with their three dimensional coordinates and other information, and had been established in the early 1970s for use by protein crystallographers. The Web server providing access to such a file has been instructed to append a MIME type header to the document every time it is requested by a browser. This header includes the string;
chemical/x-pdb
The user of the Web browser must have specified what action is to take place when receiving a file containing such a header. At its simplest, the file could simply be displayed within the browser window as a collection of atoms and co-ordinate data. This of course is where we were in the mid 1970s, as noted above. At around the same time as the World-Wide Web was coming into existence, Roger Sayle as part of his Ph.D. work in chemistry had written a molecular visualisation program called RasMol for use on various types of personal computer. This program was widely made available at no cost using the "ftp" file distribution mechanism noted above. Within a few years, thousands of chemists had acquired this program.[9] Armed with such a program, the user can now configure their Web browser to display a Web document that has an active 3D molecular model associated with it.
One of the earliest and best examples of how this can immeasurably improve science on the Internet is the "Molecules R Us" database interface to the Brookhaven database of 3D protein and large molecule structures.[10] Within seconds of performing an Internet based keyword search of this database, a rotatable and content rich display of the molecule can be on the user's screen. During 1994 and 1995, this combination of RasMol and a Web client was adopted by many chemistry-oriented Internet sites and rapidly became a de-facto standard for the subject. We started a project in June 1994 to explore how many types of molecular information might benefit from such a presentation. This included the use of hyperlinks to pdb files associated with regions of a GIF graphical image (these are called image maps) enabling association of spectral data, reaction scheme diagrams, potential energy surfaces and other graphical representations of experimental data.[11]
Unlike graphical GIF images, which Mosaic could seamlessly integrated into a text document, the 3D molecular model data could not be integrated by Mosaic, and had to appear in a separate window. In September 1995, Netscape Communications, which had developed a second generation successor to Mosaic introduced a system of "plug-ins" which allowed for the first time subject specific enhancements to be added to the basic browser functionality. In February 1996, a plug-in called Chemscape Chime was announced by the molecular database company MDLI, and was based on the RasMol code.[12] The line of HTML shown above is now replaced by
<embed border=0 src="dna.pdb" name="dna" align=abscenter width=300 height=300 spiny=360 startspin=true bgcolor="#c0c0c0" display3D=spacefill pluginspage="http://www.ch.ic.ac.uk/cgi-bin/plugin.cgi"></embed>
and allows the molecule to be displayed as part of the document ( Figure 1).

Figure 1. A World Wide Web Document, including a
"rotatable" Molecular diagram and hyperlinks (in blue).
Chime also incorporated another simple early idea of ours developed in 1994 called "chemical structure markup language" or CSML. Just as HTML can "markup" regions of a text based document as titles, section headers and lists of items for special treatment by a Web browser, so CSML could be used to impart additional information on regions of a molecule to be highlighted by the molecule display program. CSML provides a simple but effective mechanism for associating descriptive text in a document with individual atoms or regions of a molecule. Using this, we were able for example to chart the progress of the electron transport mechanism in a large protein called "photo system reaction centre". These ideas in turn provided the impetus for a much more thorough and general treatment of chemical markup which we now working on called "chemical markup language" or CML.[13]
Many other concepts are now beginning to attract serious attention, including a three dimensional version of the original HTML language called "Virtual Reality modelling language", and the "Java" portable programming language, which allows complex actions to be performed within the browser window on the content of the document, a sort of higher order intelligence to the document. A full description of these is beyond the scope of this article. Instead I will concentrate on describing a few of the unique examples of the scientific use of the Internet which really have no equivalent on either the printed page, in the laboratory or the lecture theatre. In essence, these examples are meant to demonstrate what should really be regarded as a new genre of scientific communication or perhaps more precisely collaboration.
Electronic Conferences on the World-Wide Web.
I noted that the first World-Wide Web conference was held in Geneva in May 1994. Naturally enough, all the submitted articles to this event were also posted on the Web. The chemistry workshop held during this conference also had some unique features. Although the work of a small group of pioneering Internet chemists around the world was represented at workshop, their attendance was largely virtual since funding for work and travel in this area was still scarce. Nevertheless this event paved the way for much larger scale scientific meetings in which the mechanisms of the Internet such as electronic mail could be used to discuss aspects of scientific articles. In November 1994, the Web was used to host a conference in chemometrics [14] and another in computational chemistry (ECCC-1) was organised from the USA by Steve Bachrach. [15] Chemical MIME was used for the first time at this latter event to provide active molecular models for the participants to inspect. The ECCC-1 conference subsequently spawned a CD-ROM archive of the proceedings which preserved these active 3D models, and all the information in a digital form. This in turn was abstracted by the Chemical Abstracts organisation (CAS), and has thus entered the mainstream of scientific information dissemination.
From 1995, the number of Web based chemical e-conferences grew significantly. Some, such as the "Infobahn" session at the American Chemical Society meeting in August 1995 or the WATOC conference in July 1996 provided electronic posters as an adjunct to a much larger physically attended event. Others continued the electronic only theme, such as the organic chemistry focused ECTOC-1 which we organised and which was also subsequently published as a CD-ROM and abstracted by CAS, and most recently the ECHET96 event (Figure 2). [16]
Figure 2. The "Home" Page of an Electronic Conference.
The scale of such conferences is illuminating. A total of 77 articles were submitted to ECTOC-1, some 300 people "registered" for the e-mail discussions and around fifty e-mail comments were posted regarding the submitted articles, during a discussion period which lasted four weeks. Perhaps most significantly, we were able to collect accurate usage statistics for the conference by analysing what is called the server log file. Thus during a 9 month period, in excess of 10,000 different computer systems had requested one or more documents from the ECTOC conference server, and we provided a service so that an author could find out how many "hits" their own paper had attracted. I have to confess that I used such statistics in support of a funding application (perhaps this impressed the referees, because the grant was funded!).
Such mechanisms for measuring interest in Internet based information have also attracted the interest of commercial publishers, who had originally been quite slow in their use of such venues. This actually raises a quite profound issue. There is no privacy for anyone who looks at a Web based document on the Internet, although many users of the system probably do not realise this. This is a serious issue for anyone who would not want others to know what documents they might express an interest in. Our own production of a CD-ROM based on ECTOC-1 was in part based on providing privacy to anyone who would wish it.
Whilst the technical sophistication of electronic conferences grew, some interesting sociological phenomena emerged. [17] Participants began to be concerned at the permanence of their contribution, and whether it would "count" towards their subsequent career advancement, or their chances of succeeding with their next funding application. The establishment still regarded the only true indicator of scientific achievement as being the "printed" journal or book. The editors of some prestigious printed journals issued guidelines saying they would not accept any materials that had previously been mounted in electronic bulletin board form. In partial response to such concerns, the guidelines for some recent e-conferences assured their contributors that the material would be subsequently removed from the Internet and re-published using the entirely conventional medium of the printed journal, thus ensuring the loss of active 3D molecular models and other information content unique to the Web. In effect, what we were seeing was the e-conference as a global model for a co-operative scientific peer review mechanism rather than any form of permanent publication. Whether the emphasis will continue to move in this direction, or whether the e-conference will start to blur with electronic journals remains to be seen. The entire subject of how electronic journals will develop is too complex to discuss here, since a whole new range of issues is raised such as permanence, immunity to technical developments, charging mechanisms and privacy. [18] Certainly, electronic conferences have thus far served as fascinating test-beds for many of these issues, and the impact in their short lifetime has already been substantial.
Distributed Teaching Models on the World-Wide Web.
Another area where Web based models has also had a distinctive impact has been its use to distribute teaching materials, and furthermore to receive a response from the students. Unlike pure scholarly research, a great proportion of teaching material developed by individuals has traditionally been rarely seen beyond the audience present during the lecture when it is delivered. The traditional model for disseminating such knowledge in a considered manner on a wider scale has remained the text book. The lecture in particular is often used to impart as much factual information as can be delivered to students in 50 minutes or so, and it is faintly absurd that this would result in one hundred or so hurriedly taken and presumably very similar sets of lecture notes. The students are often more concerned with manual transcription of these facts rather than their comprehension, and the lecturer does not always concentrate on imparting this comprehension.
When the Web began to be widely known from 1994 onwards, "virtual schools" and "virtual libraries" were a feature of the content almost from the start. Some provide a rich source of reference material for teachers to use in conventional lectures and as backup material. There are many exemplary examples of this, but I will merely note here one of the best in my own area of chemistry, namely the WebElements Periodic table maintained by Mark Winter at the University of Sheffield.[19] This contains an enormous wealth of material, but presented to the reader in a clear and simple manner by extensive use of hyperlinks and other Web-derived mechanisms, and of course indexed so that individual facts are easy to find. This model is largely maintained by a single individual, but other models are truly distributed, such as the CAUT project in Australia[20] to develop and integrated set of projects and courses in the area of computational chemistry. This involves a consortium of Australian universities, which together can achieve a critical mass and level of quality that could not be done in isolation.
An even large scale project is exemplified by the Principals of Protein Structure (PPS) course organised during 1995, where course material was contributed by more than 40 individuals from all parts of the globe, and which attracted more than 100 registered students.[21] Course work was set regularly, and submitted by electronic mail, or in the form of a URL reference to a server maintained by the student themselves. A phenomenon called the "MOO", in which a group of people can discuss a topic in real time by typing comments into a shared area from a keyboard, was used extensively. It is interesting that the original NCSA shared whiteboard project that antedated Mosaic has not made a major impact in this area. Curiously, few of the individuals involved in the PPS project ever actually met in real life, and quite possibly did not know aspects of the people they were interacting with, such as their sex, age and background. Another innovative feature was the use of a "Hyperglossary", where any individual could submit a hyperlinking entry between two or more terms or definitions used in the course. This course was an actively evolving entity, where consultants and students alike could contribute to the whole, under the watchful gaze of a curator. Undoubtedly the experience and knowledge provided to the course by the collection of individuals represented a far more effective and up to date way of imparting state-of-the-art knowledge then the traditional lecture-class model.
Other types of subject resource have also evolved. Sometimes material is made available via the Web by an individual which would not have the critical mass to form a complete course. However, collections of such materials from over the world would be much more valuable. Such collections also have the value that their quality can be mediated or edited by a knowledgeable individual. Again many such collections have evolved, and some continue to be actively maintained, some do not.[22] Our own work in this area included initiating a "molecule of the month" collection, where a short story is told about a molecule of interest, and illustrated with a rotatable model of the system. A number of chemistry faculties have contributed to this collection,[23] which provides a source of contemporary material for chemistry educators all over the world. Another resource which has not yet been widely adopted is the placing of entire lectures on the Internet. For example, for more than two years now, many of my public talks have been available in this manner.[24] Doing this however has not decreased real contact with people, in fact quite the reverse, and I still believe that such a global forum for disseminating the accumulated experience of individuals has much potential.
The Future of the Scientific Internet.
Despite the impression that might be generated of the Internet in popular magazines and television programs of a badly organised pandemonium of pornography, advertising and commercial activities, there is a significant core of serious application to areas such as science and to chemistry. Currently, the phenomenon is too young for us to know what experiments will survive and flourish. We do not even know yet if there is any equivalent to Darwinian natural selection that will ensure the extinction of unsuccessful experiments, or whether this will be driven by purely commercial forces. In any immature mechanism, there is bound to be a fascination with the style of presentation rather than its content. Few are yet certain how to archive this mass of material on any significant time scale. Professional publishers are still uncertain of the form that commercial models will take, or indeed whether they will have the major role to play. Academics are not sure yet whether they will be able to base their career structures on any significant form of Internet activity, and where to draw the dividing line between the need for a virtual interaction with someone and the need to meet them physically.
I am sufficiently optimistic to predict that by the turn of the millennium, many of these problems will be solved, and we will be agonising about new problems as yet undreamed of. Perhaps my closing remark should be that at least I can be certain that because this article is appearing in the conventional form of print, it will still be readable then.
Acknowledgements.
Above all, the Internet is a collaborative medium, and I must thank the colleagues whose names are noted in the text above, for the distinctive and creative impact they have made to this new genre. I also gratefully acknowledge financial sponsors, including GlaxoWellcome (Stevenage), the JISC e-lib programme for funding our CLIC e-Journal project, British Telecom for supporting our Virtual Library project and McDonnell Information Systems for help with our Java project.
Biography of the author.
Henry S. Rzepa has obtained both Ph.D and D.Sc. from Imperial College. His research has covered the areas of quantum chemical modelling of organic reactivity, structure and mechanism. He has published over 160 scientific papers in these areas, and in 1995 was awarded the Joseph Loschmidt Prize of the Royal Society of Chemistry. Since 1990 he has developed the use of the Internet for furthering scientific communication.